Getting started
Introduction video:
Still have questions? Check out our other short pdf2Data videos for tips, tricks, and best practices
This is an introduction to pdf2Data, the rules-based, on-premise solution to automate PDF parsing and data extraction. Empowering users to unlock the full potential of their PDF data, pdf2Data streamlines your IDP workflow and boosts your productivity.
Many businesses need to automate the identification and extraction of important business data contained within PDF documents, to avoid manual copy-paste operations which are error-prone and time-consuming. To automate these processes and reduce costs, those files should be converted into a structured format and cleared of any useless data.
By offering an intuitive identification and extraction interface, pdf2Data allows developers to focus their efforts on the utilization of extracted business data rather than how to identify and extract the desired values. Utilization of pdf2Data for PDF parsing significantly simplifies the extraction workflow, reducing the amount of code developers must write, test, and maintain.
With the pdf2Data Editor, extraction templates can easily be created and maintained by Developers and Subject Matter Experts (SME) alike. These templates can be easily created and maintained even by non-technical users.
Otherwise, read on!
How it works
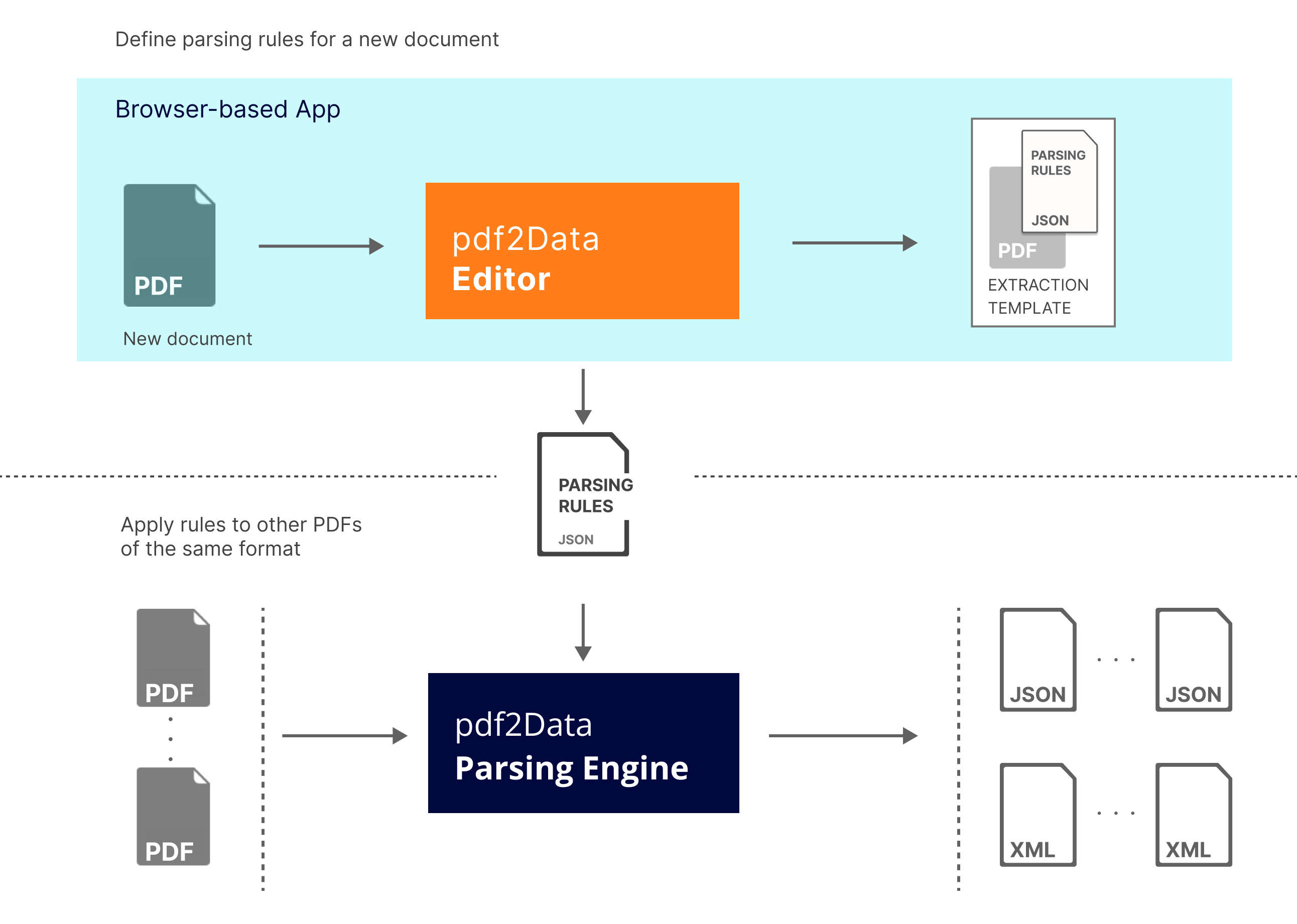
- For a new document an extraction template based on a reference PDF must be created. This can be done using the intuitive pdf2Data Editor.
pdf2Data Editor can be deployed in two different modes:
- standalone, which contains only template editing functionality,
- full, with an additional template and user management facility.
- For all other PDFs of the same type. In the Parsing Engine, parsing rules from the extraction template are automatically applied to input PDF files and return the required data in an easily reusable structured format.
Terminology
Extraction template
Each extraction template is a combination of the following two elements:
- A reference PDF to build and test parsing on.
- Several data fields (parsing rules) which define the way data will be extracted.
Once an extraction template has been created, it is then used as a basis for future PDFs matching the template.
For pdf2Data you normally create a data field for each value you want to extract.
Data field
A data field has an associated search region, a parsing pipeline (or a parsing rule), and a bounding box.
- Search area By default, pdf2Data applies a parsing pipeline to the entire document. You can reduce the search area by specifying page(s) and/or by drawing a custom area on the document canvas. Read more...
- Parsing pipeline. This is created from the predefined pdf2Data selectors.
The data field's extracted value is the result of applying the parsing pipeline to a PDF document. During the data extraction process, each selector receives data from the previous selector in the pipeline, converts it to the necessary format, filters the data out, and sends the filtered data to the next selector. The data extracted by a data field is the result of the last selector in the pipeline.
Integration
Depending on your needs, the pdf2Data Parsing Engine is available in 4 different forms:
- Java SDK (Maven package)
- .Net SDK (.Nuget package)
- Command line interface
- RESTful service (available as a Docker container)
Regardless of which one you prefer, the process of using the pdf2Data Engine essentially consists of 3 steps (please see the documentation of the specific engine you're using for more details).
- Upload template (containing your parsing rules).
- Retrieve all PDF files you need to process
- Process those PDFs sequentially and get the results.
For the rest, you have full power in defining (and coding) the best strategy to map input PDFs to specific templates, and the way extraction data will be utilized in your workflow.